このセクションでは、必要なスレッド化機能を説明することによって Maya API が提供する機能について説明し、Maya が提供するサンプル プラグインの一部の使用方法を紹介します。
Maya には、スレッドの作成、管理、ロックを支援する多数のスレッド化クラスがあります。これらのスレッド化クラスは、Intel の TBB スレッドに基づいて構築されており、内部処理に使用されます。また、ネイティブ スレッドに類似した API をプラグイン作成者に公開します。これらのクラスでは、プラグイン作成者が自分のプラグインで TBB を直接使用する必要はなく、TBB に精通する必要もありません。これらのスレッドは実際は Maya 内部スレッドであるため、適用されているスレッド数の設定が尊重され、プラグイン自体がスレッド化されたときに多数のアクティブ スレッドが作成される問題が回避されます。また、TBB によるスレッド化の実装方法が原因で発生する可能性のあるオーバーサブスクリプションの問題からも保護します。
アーキテクチャはオブジェクト参照カウントを使用してメモリ管理を支援し、すべてのユーザが処理を完了するまでオブジェクトの割り当て解除を遅らせます。API 関数のコールが成功するとインタフェース ポインタが返され、コールする側は処理が完了したらそのインタフェースに対して release() をコールします。これを実行しないと、メモリ リークが発生する場合があります。
このクラスはスレッド プールを作成または再利用します。スレッドの作成と削除には多くのリソースを要するため、可能な場合はスレッド プールを利用し、プラグインのコールごとにスレッドを再作成せずにコールの間スレッドを保持することをお勧めします。スレッド プールは参照がカウントされるため、プラグインの initialize() メソッドでスレッドを作成してアプリケーションの継続期間は保持してから uninitialize() メソッドで解放します。ネイティブ スレッド化実装には共通のメソッドが用意されているため、プラグインをネイティブ スレッドからこの API に移行することが可能です。
実装には、引数として関数ポインタを取る分岐結合コンテキストの作成が必要です。この関数は、指定された問題をTBB によってが内部処理でスレッドにマップされる小さいチャンク(タスク)に分解する機能を実装する必要があります。
TBB の内部使用は、MThreadPool で作成されたスレッド化分岐結合領域をオーバーサブスクリプションを生じることなくネストできることを意味します。TBB はこれらをコアにマップすることで、すべてのタスクを並列にスケジュール設定します。
このクラスには、ネイティブ スレッドに共通のメソッドが用意されており、独立した非同期タスクをスレッドにマップすることが可能です。現在の実装は、このインタフェースに対してスレッド プールを使用するのではなく、非同期タスクごとに新しいスレッドを作成します。これはオーバーサブスクリプションが発生する可能性があることを意味しているため、非同期スレッドの数と同時に実行される作業量の管理には注意が必要です。
createTask() メソッドは、非同期タスクを実行する関数ポインタと、分岐結合または他の信号送信機構を実装するために開発者が使用できるコールバック関数のポインタも取ります。
サンプル プラグイン threadTestWithLocksCmd.cpp を参照してください。このプラグインは Maya に付属しています。前に説明したスレッド プールの例と比較して、この実装では DecomposePrimes のような個別の関数の作成は不要です。これはネイティブ スレッド化 API に非常によく似ています。ただし、非同期スレッド化インタフェースには、結合メソッドは用意されていません。このサンプルは、コールバック関数でバリアを実装することで(WaitForAsyncThreads)、同等の機能が実装される仕組みを示しています。
関数 Maya_InterlockedCompare() は、Maya API 提供の MAtomic.h ヘッダーでアトミック compareAndSwap() メソッドを使用するとより効率的に実装できます。
MMutexLock と MSpinLock はシステム ロックです。MMutexLock は、pthread_mutex_lock (OSX と Linux)と EnterCriticalSection (Windows)を使用します。これらの違いは、ミューテックス ロックの方が動作の負荷は大きくなるがロックが保持されると CPU リソースが不要になるという点数です。スピン ロックは負荷の軽い操作ですが、待機中に大量の CPU リソースが必要です。したがって、待機時間が短い場合はスピン ロックを使用します。これらのクラスはデストラクタでロックを解放します。つまり、明示的な解放は不要で、ロックされたコードに例外がスローされた場合でもロックは安全に解放されます。
関連のないコードのロック オブジェクトの各種インスタンスを使用することをお勧めします。多数の異なる場所で単一のロック オブジェクトを使用した場合、関連のないタスクを処理していてもスレッドがブロックされることがあります。
Maya API は MAtomic.h と呼ばれる API ヘッダにアトミック操作の実装を収め、クロスプラットフォームのアトミック操作機能を備えています。以下は、使用可能なアトミック操作のリストです。詳細な説明は、そのファイルと Maya API クラスの関連資料に記載されています。
MAtomic::preIncrement()
MAtomic::postIncrement()
MAtomic::increment()
MAtomic::preDecrement()
MAtomic::postDecrement()
MAtomic::decrement()
MAtomic::set()
MAtomic::compareAndSwap()
以下は、64 ビット版 Windows でのスピン ロックとミューテックス ロック、アトミック操作のコストに関するパフォーマンス値を示しています(OSX を除けば、他のプラットフォームも同様にはるかに低速です)。これらの数値を生成するプラグインは threadingLockTests と呼ばれ、ユーザが独自のシステムでテストを行うためのサンプル プラグインとして Maya に付属しています。これには OpenMP をサポートするコンパイラが必要です。このプラグインは、ロックされた領域内でコードがほとんど実際の並列処理を実行しないという極端な例です。ただし、激しい競合下でのこれらのロックの相対コストを示しています(ロックの競合は、あるスレッドがすでに保持しているロックを別のスレッドが取得しようとする場合に発生します。実行中のスレッドが増加すると、ロックの競合が起こる可能性が大幅に高まります。競合が激しくなると、パフォーマンスは大幅に低下します)。
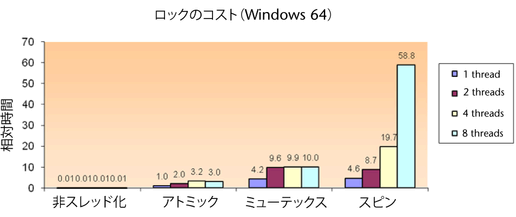
さまざまなミューテックス ロックにアトミック操作の利点があります。また、ロックを実行しないコードは、アトミック実装よりもはるかに高速になります。可能な場合はロックを回避することをお勧めします。ロックを使用する場合はアトミック操作を使用します。アトミック操作を使用できない場合にかぎり、フル ミューテックス ロックまたはスピン ロックを使用します。
ロックの粒度は、それ自体が非常に複雑な項目です。一般的には、多数の並列処理が可能なため、疎粒度ではなく細粒度のロックが最も適切です。ただし、ロックの粒度が細かすぎると、膨大なシステム時間を消費し、コードが非常に複雑になります。課題は、ロックの粒度の最適なバランスを見つけることです。粒度が粗いロックは最も簡単であるため、このようなロックを初めて使用する場合にお勧めします。後は、パフォーマンスが向上しなくなるまで、徐々にロックの粒度を細かくしていきます。
ロック操作で最悪なのは、アプリケーションが処理をまったく進行できない場合です。
Maya に付属のプラグイン splatDeformer はスレッド化デフォーマの実装サンプルです。このサンプルは、Maya ネイティブ API ではなく OpenMP を使用します。これは、スレッド化実装そのものではなくデフォーマのスレッド化に注目するためであり、OpenMP では、スレッド化の実装のために追加する必要のあるコード量が最小であるためです。
デフォーマは Maya スカルプト デフォーマに少し似ています。デフォーム メッシュは選択したメッシュの修正に使用できます。このアルゴリズムは、デフォメーションをデフォーム オブジェクトの最近接ポイントにスナップすることでメッシュのすべてのポイントに適用します。最近接ポイント操作は計算集約型の処理であるため、オーバーヘッドがスレッド化のあらゆる利点を帳消しにしてしまう一部のより単純なデフォーマとは異なり、スレッド化に適した選択肢です。
拡張性はコードの順次部分によって制限されます。このため、スレッド化領域外でコードを最適化することが重要です。たとえば、最善の方法としては、DG から可能なかぎり大きなチャンクでデータの取得と設定を行うことが挙げられます。これにより DG のオーバーヘッドが最小限に抑えられます。複数のメソッドが MFnMesh に追加され、1 つの操作でさまざまなタイプのコンポーネントをすべて取得できるようになりましたが、特にこのような用途に適しています。当然ながら、一度に 1 つのエレメントを更新する iterator アプローチと比較すると、これらの配列は計算メソッド中は維持する必要があるため、メモリの使用量が増大する危険性があります。メソッド MFnMesh::getRawPoints は、ポインタを内部データに直接返すことによって最大速度を実現し、メモリのオーバーヘッドも回避します。
一部のデフォーマはウェイトをデータブロックにキャッシュします。データブロックからの読み取りは低速で、スレッドセーフでない可能性があります。デフォーマのウェイトはフレーム単位では変化しないことが多いため、このような場合、一度ウェイトを読み取ってデフォーマ クラス内のローカル配列に保存してから、キャッシュしたウェイト値を使用してスレッド化デフォーマの評価を行うのが最善の方法です。
一般的なコーディング パターンは、シングルトン オブジェクトの作成、あるいはソルバのグローバル データの初期化です。通常は以下が最も簡単な操作です。
static solver* singleton = 0
if (singleton == 0) {singleton = new Solver();
}
ただし、スレッド化コードの場合は非常に困難な問題になります。このパターンを実装するための最善のアプローチに関しては多くの文献がありますが、問題はオプティマイザが明らかにスレッドセーフな実装を損なうことが多いということです。明白なソリューションはロックの使用ですが、最初の構築にしか必要のない負荷の高い操作です。
一般的に、初期化のオーバーヘッドがあまり大きくない場合、プラグインの initialize() メソッドに組み込むと順次実行が保証されます。
オブジェクトが大規模であるかまたは構築に大きなリソースが必要な場合、あるいはプラグインが常に実行されるわけではない場合は、遅延評価を使用して必要なときだけオブジェクトを初期化します。以下に、このような場合に便利な実装を示します。ここでは、Maya に付属の MAtomic API クラスを利用します。
static Solver* singleton = 0
if (singleton == 0) {Solver* solver = new Solver();
if(!MAtomic::compareAndSwap(&singleton, 0, solver)) {delete solver;
}
}
コール時に複数のスレッドが if 条件を入力し、場合によっては同時に複数のソルバを作成します。compareAndSwap に到達した最初のスレッドは solverSingleton ポインタを新規ソルバのアドレスに設定し、後続のすべてのスレッドはソルバの作成終了後そのソルバのインスタンスを削除します。これは一見すると無駄が多いように思われますが、パフォーマンスに影響があるのは開始時のみで、後続のすべてのコード コールは単純なポインタを実行するだけでロック処理はまったく必要ないため、実際は非常に効率的です。
ソルバ コンストラクタに複数のスレッドが存在すると危険であるため、以下に代替テンプレートを示します。
static Solver* singleton = 0
static int doneInit=0;
if(MAtomic::compareAndSwap(&doneInit, 0, 1)) {singleton = new Solver();
doneInit = 2;
}
while(doneInit != 2) {}; // spin-waitこのコードではソルバは必ず 1 度だけ初期化されます。コンストラクタが solver ポインタの初期化を実行したがその処理がまだ完了していない場合に他のスレッドのオブジェクトへのアクセスを防止するために、オブジェクトが完全に初期化されるまで終了しないスピンウェイト ループが適用されています。このアプローチの欠点は、アトミック操作が必要で、後続のすべてのコールに対して、なくとも 1 回の while ループのトラバースが必要になることです。また、コンパイラについては doneInit=2 の行をコンストラクタより上に配置しているという懸念事項があります。このため、ソルバ コンストラクタ コールに関する追加ロックが必要な場合があります。
Maya API は非常に広範なため、現時点ですべての関数とクラスがスレッドセーフかどうかを示すことは不可能です。このセクションでは、スレッド化コードで頻繁にコールされる主要なクラスをいくつか説明します。
残念ながら、メソッドがスレッドセーフであると想定することは危険です。関数がインラインで直接確認できるものでなければ、常にコードがスレッドセーフではない危険性はあります。照会メソッドでさえも、照会により修正された内部状態をクラスが保存する場合があるため、安全ではないことがあります。
遅延評価を使用するクラスもあるため、特定のメソッドは、スレッド化領域外でコールして内部データ構造を更新することで「準備」する必要があります。たとえば、MFnMesh::getVertexNormal は、法線が最新であることを確認し、最新でない場合は再計算します。このように、法線が最新でない場合、この関数に対して 2 つの同時コールが発生するため危険性が生じます。ただし、1 つのコールが実行されて内部データ構造が更新されると、その初回の準備コール以降、オブジェクトが修正されないかぎり後続のコールはスレッドセーフになります。
配列クラスは読み取りアクセスの場合は安全です。書き込みの場合、set() メソッドは配列のサイズを変更しないため安全です。ただし、 append()、insert()、remove() は配列のサイズを変更する可能性があるため、安全ではありません。
コンテキストも重要です。一連の MDataHandle オブジェクトを配置するだけで、データブロックからオブジェクトを抽出するというスレッドアンセーフな部分をすでに実行していることになります。第 1 レベルの危険は、データブロックがなかなか作成されないため、まったく存在しない場合には 1 つのスレッドのみでそれを実行する必要があることです。第 2 レベルの危険は、データを読み取るためのハンドルを取得するときに、データブロックが評価をトリガーする可能性があることです(inputValue(...) メソッドを使用する場合)。これには独自のスレッドの安全性に関する問題があります。
このクラスは事実上データブロックへのスマート ポインタであるため内部状態を保持しており、複数のスレッドで同じハンドルを使用するときが明らかに危険です。jumpToElement() への並列コールに続いて照会コールを行う複数のスレッドはスレッドセーフではありません。